分布式ID生成方案
业务系统对ID的要求有:
- 全局唯一;
- 趋势递增:Mysql InnoDB采用的是聚合索引,多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上尽量使用有序的主键保证写入性能;
- 单调递增:保证下一个ID一定大于上一个ID;
- 信息安全:ID无规则;
1.数据库自增字段
最常见的方式,利用数据库,全库唯一。
优点:
- 简单,代码方便,性能可接受;
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 不同数据库语法和实现不同,数据库迁移的时候或多数据库支持的时候需要单独处理。
- 单个数据库读写分离或者一主多从的情况下,只有一个煮开可以生成。单点故障风险。
- 性能达不到要求的情况下,比较难扩展。
- 分库分表有点麻烦。
PS:
数据库自增Id需要锁表。
优化:
- 针对主库单点,如果有多个Master库,则每个Master库的起始数字不同,步长一样。可以降低ID生成数据库操作的负载。水平扩展比较麻烦,如果有100台机器怎么办。
2. UUID(Universally Unique Identifier)
常见的方式。
优点:
- 简单。代码方便。
- 生成ID性能非常好,基本不会有性能问题。
- 全球唯一。数据迁移,系统数据合并等情况下,从容应对。
缺点:
- 没有排序,无法保证递增;
- 往往是字符串存储,查询效率低。
- 存储空间比较大,海量数据库的话,要考虑存储量的问题。
- 传输数据量大;
- 不可读。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
3.snowflake算法
twitter生成全局ID的算法策略。
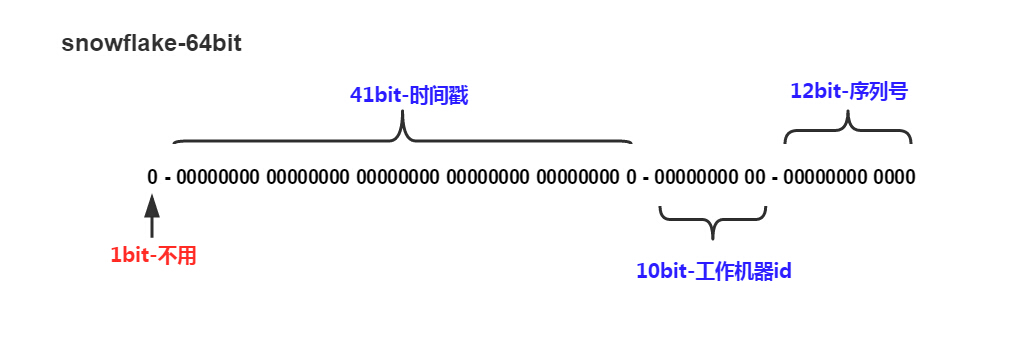
第1位留空,41位表示时间,10位表示工作机器ID,12位的序列号。通过部署多个ID生成器,为各个业务系统生成全局唯一的Long型ID。
优点:
- 易操作,有序。
缺点:
- 需要独立部署ID生成器。增加维护成本。
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
4.Redis 生成Id
主要依赖Redis是单线程的。
优点:
- 不依赖数据库,灵活方便,且性能好。
- 数字ID天然排序。
缺点:
- 编码和配置的工作量比较大。
6.MongoDB的ObjectId
和snowflake的算法类似。
时间戳+机器ID+进程ID+序列号-》ObjectId对象
优点:
- 本地生成,有序,成本低;
缺点:
- 使用机器ID和进程Id,64位Long无法存储,只能生成特殊的ObjectId对象。
7.Segment方案
使用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。区分业务bizType。
优点:
- 方便的线性扩展,性能OK;
- ID是递增的8byte的64位数字。满足数据库存储的主键要求。
- 容灾性高:服务内部有号段缓存,即使DB宕机,短时间依然可以对外正常提供服务;
- 可以自定义maxId大小,方便从原有ID上迁移;
缺点:
- ID不够随机;
- TP 999 数据波动量大,当号段使用完之后还会hang在更新数据库的IO上。
- DB宕机会导致整个系统不可用。
优化:
当号段即将用完的时候,启动线程去更新下一个号段。
解决时钟回拨问题,可以直接不提供服务直接返回ErrorCode。等时钟追上即可。或者报警。
参考文章:
https://maimai.cn/article/detail?fid=203755745&from=single_feed